

Benjamin Treynor Sloss (VP Engineering, Google) is generally credited with coining the term “site reliability engineering (SRE)” in 2003 and it’s buzzworthiness has grown in the past few years.
Beyond the buzzword, how do you know if your company is ready to implement SRE? Here are some signs that you need to consider getting started:
- Your customers aren’t happy with your website’s uptime, performance, and stability.
- Your support team is overwhelmed, causing SLA breaches, unresolved tickets, and increased downtime.
- Your system has so many recurring incidents that your support team is experiencing alert fatigue and burnout.
- Your engineers are taking a reactive approach to incident management instead of making proactive improvements to system stability and resilience.
- Your engineers are handling recurring incidents manually, resulting in increased operational toil and decreased time available to focus on developing new innovative features.
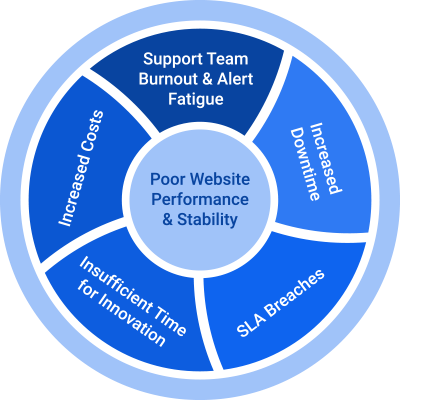
If any (or all) of the above strike home, you’re ready to start implementing SRE. Use this blog as your beginner’s guide.
What is SRE?
Site reliability engineering (SRE) is a culture and a set of practices to ensure system reliability and maintainability. The SRE team implements best practices, automation, and metrics to find creative solutions when sites slow to the point of user frustration. The team strikes the right balance between reliability and feature velocity.
In its SRE Book, Google explains,
“It’s impossible to manage a service correctly, let alone well, without understanding which behaviors really matter for that service and how to measure and evaluate those behaviors. To this end, we would like to define and deliver a given level of service to our users….”
Organizations need well-defined reliability targets, which are known as Service-Level Objectives (SLOs). These objectives are measured by Service-Level Indicators (SLIs).
It’s critical to maintain a delicate balance between change requests, feature releases, and site reliability. If an organization meets its SLOs, it can make prudent decisions on the percentage of time its engineers devote to innovating products and developing new features. Without SLOs, innovation can be disrupted by infrastructure instability and conflicts in change management and event handling.
All the teams that are part of a project (e.g., the operations team, product manager, developers, and the SRE team) need to concur upon a standard definition and suitable level of reliability and the action plan in case of failure to achieve that reliability level. During that discussion, the teams need to address:
- What does availability mean to us?
- How do we define user happiness? Convert availability/happiness into metrics.
- How will we track availability and customer happiness?
- Which Service-Level Indicators (SLIs) reflect failure?
- How will we mitigate failure?
A deeper dive into SRE terminology
Service-Level Indicator (SLI) — a quantitative measure of some aspect of the level of service.
An SLI defines whether you are meeting your Service-Level Objectives (SLOs). It measures how your service is performing by defining parameters that signify the successful transactions handled by the service over a defined time interval. An SLI is the number of good events divided by the total number of valid events, multiplied by 100%. For example:
You can query SLIs using monitoring solutions, e.g., Datadog, Grafana, New Relic, Prometheus, etc. Commonly used SLIs are availability, throughput, and latency. The rate of queries passing successfully and unsuccessfully are evaluated as SLIs.
SLIs represent the experience of the customer and are key metrics for assessing the performance of a company. A well-constructed SLI provides a view of the service that approximates the customer’s experience.
Service-Level Objective (SLO) — a target value or range of values for a service level measured by SLIs.
The primary responsibility of the SRE team is to maintain reliability and prioritize goals and tasks as defined by the SLOs. An SLO sets a user’s expectations about how a service will perform. SLOs can also be thought of as benchmarks for the SLIs.
An SLO describes the best possible and reasonable performance level. It’s unrealistic to set a reliability target at 100% because complex systems operating at scale will have failures. The time spent trying to achieve 100% reliability would have an adverse effect on innovation and the speed of delivering new features. The most observed causes of outages are deploying new features, hardware, and making changes in service.
This table shows how much downtime is permitted to reach a given SLO availability level:
| SLO ALLOWED DOWNTIME | DAILY | WEEKLY | MONTHLY | YEARLY |
| 99.9% | 1m 26s | 10m 4s | 43m 49s | 8h 45m 56s |
| 99.95% | 43s | 5m 2s | 21m 54s | 4h 22m 58s |
| 99.99% | 8s | 1m 0s | 4m 22s | 52m 35s |
SRE teams can clearly see when their service performance is degrading, and they must know what actions they need to take to ensure users’ happiness. Note: SLOs are for internal use and should always have stricter targets than SLAs, so the SRE team can react quickly to avoid violating agreements.
Service-Level Agreement (SLA) — a business-level agreement/contract between the customer and the service provider.
An SLA is based on promises by the service provider for the availability and performance of a service based on performance metrics (SLOs). It states the consequences (penalties) of breaching the SLA by failing to achieve those metrics. Penalties can be free credits, free service, money refunds, etc.
Generally, SLOs and SLAs are similar in terms of metrics, but SLO targets should be stricter than SLAs, as mentioned earlier. For example, if you set an internal target (SLO) of 99.9% availability, you may promise 99.5% availability in the SLA. SLAs are business documents, so the SRE team is not directly involved in creating and defining the SLA but is directly involved in defending and protecting the SLA.
Error budget — how much time you’re willing to allow your systems to be down.
The error budget is calculated as 100% minus the SLO target percentage. If your SLO target is 99.9%, the error budget is 100% – 99.9% = 0.1%. If your service receives 100,000 requests per month, at a 99.9% SLO you’re allowed 1,000 errors per month.
Based on these values, the SRE team makes data-driven decisions by choosing and prioritizing what and when to deploy or make system changes, staying within the error budget defending the SLO.
Are you having challenges with system availability and reliability? Are your engineers spending too much time supporting systems when you need them focused on innovation and new features?
We’d love to help you to get started with Site Reliability Engineering. Learn more about nClouds’ SRE Services here, or contact us today.

View this on-demand webinar featuring SRE experts from nClouds & Datadog
How DevOps Teams Use SRE to Innovate Faster with Reliability.


