

In this blog, I’ll provide a step-by-step tutorial on automating a runbook to reduce MTTR by using Amazon EventBridge (EventBridge) and Datadog. Datadog is used as a monitoring tool, and EventBridge is used to remediate issues and automatically resolve any alerts.
EventBridge is a serverless event bus. It makes building an event-driven workflow for applications easier by adding rules to your event buses and associating your event buses with targets.
What is a runbook?
IT runbooks document approved processes. Runbooks are comprehensive manuals for handling repetitive tasks or incidents within a company’s IT operations process. IT system administrators and operators use runbooks to implement standardized routines to start, supervise, debug, and stop a system.
Runbooks may be manual, semi-automated, or fully automated. Automated runbooks enhance Site Reliability Engineering (SRE) practices by automatically performing remediation processes with negligible downtime and reducing the need for human intervention. In other words, automation minimizes disturbance in application performance and reduces stress for the DevOps, SRE and operations teams by eliminating manual and repetitive tasks. Therefore, event-based runbook automation is crucial to increase company efficiency and reduce Mean Time to Repair (MTTR).
Step-by-step tutorial
To begin, let’s assume that we want to ensure 24/7 availability for our NGINX web server. And, if it crashes, NGINX will need to rest. We also need to track logs during the crash for auditing and root cause analysis. Also, for this setup, NGINX is running on an Amazon Elastic Compute Cloud (Amazon EC2) instance with an AWS Systems Manager Agent (SSM Agent) and a Datadog Agent installed. Instance roles allow the SSM Agent to run command permissions and the Datadog Agent to perform NGINX process monitoring.
Datadog sends alert notifications through the Agent’s run command to execute a script that verifies the service status and restarts the service if it crashes. It retrieves the server’s recent access and error logs and sends this information to the proper Slack channel.
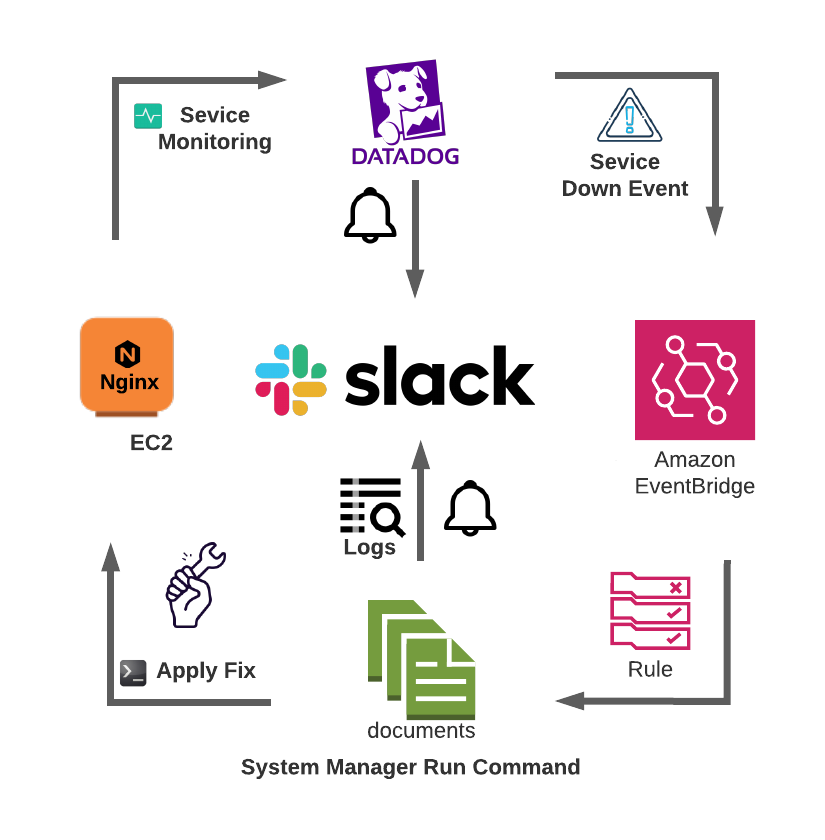
Slack setup: To create a new custom Slack app, choose Create from scratch and pick a workspace to develop your app. On the next page, navigate to Oauth and permissions, define Bot Token Scopes, and choose file.write. Install the app in the workspace. Now, invite the app to the channel by typing \invite in the channel, and add the app that you created.
Datadog setup: Enabling EventBridge integration on Datadog is easy to do. However, you may need to add events:createeventbus permission in the Datadog role in your AWS account and install the integration. More details on integration are on Datadog’s integrations page.
Once the integration is complete, you can navigate to Amazon EventBridge integrations and add a new event bus in the same Region where you have Amazon EC2 running. Datadog creates one EventBridge bus for you on AWS, and you can verify it on the EventBridge console. A new bus will appear in the following format: aws.partner/datadog.com/<EVENT_BUS_NAME>
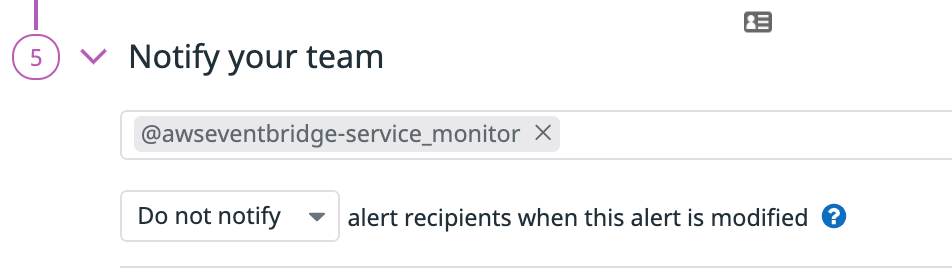
Now, we need a Datadog monitor that can trigger an alert whenever the service goes down. We can send this notification to our newly created EventBus:
@awseventbridge-<EVENT_BUS_NAME>.
Below you can see a process monitor for NGINX that I created in Datadog. I’ve selected my Slack channel and Amazon EventBridge as notification recipients.
AWS Systems Manager Parameter Store setup: Navigate to Parameter Store on the AWS Systems Manager console and create a new parameter. Change the type string to SecureString. Copy the Slack Bot User OAuth Token and paste in the value.
SSM document setup: Use the following bash script to restart NGINX and send its logs to the Slack channel. Create a new bucket or use an existing bucket and store script service_restart_script.shservice_restart_script.sh in Amazon Simple Storage Service (Amazon S3) with the following content:
#!/bin/bash
Token=$(aws ssm get-parameter --name $2 --with-decryption --region us-east-1 --query "Parameter.[Value]" --output text)
Channel=$1; ErrorLogs=/var/log/nginx/error.log; AccessLogs=/var/log/nginx/access.log; SlackApiUrl=https://slack.com/api/files.upload
function SlackBot() {
curl -F "content=`tail -10 $ErrorLogs`" -F "initial_comment=`echo -e \"$1 \n FYI Below are the recent error logs:\"`" -F "filename=error.log" -F "channels=$Channel" -H "Authorization: Bearer $Token" $SlackApiUrl
curl -F "content=`tail -10 $AccessLogs`" -F "filename=access.log" -F "channels=$Channel" -H "Authorization: Bearer $Token" $SlackApiUrl
}
if ! pidof nginx > /dev/null; then
service nginx restart > /dev/null
if pidof nginx > /dev/null; then
SlackBot "Nginx was not running!.Restarted Successfully!"
else
SlackBot "Unable to Restart Nginx. Please check manually."
fi
else
SlackBot "Checked Nginx already running."
fi
To keep the SSM Command document smaller, I keep this bash script on Amazon S3. We will define an action to download the script from Amazon S3 in YAML.
Open the AWS Systems Manager console again and navigate to Documents under Shared Resources. Create a new SSM Command document and define the actions and parameters. Define the document in JSON or YAML format.
---
schemaVersion: '2.2'
description: "restart nginx on trigger"
parameters:
sourceInfo:
description: "(Required) The information required to retrieve the script from the S3."
type: StringMap
slackToken:
description: "(Required) SSM parameter name to retrieve the Slack token from the SSM parameter store"
type: String
slackChannel:
description: "(Required) Slack channel name"
type: String
mainSteps:
- action: aws:downloadContent
name: downloadContent
inputs:
sourceType: S3
sourceInfo: "{{sourceInfo}}"
- action: aws:runShellScript
name: runShellScript
inputs:
timeoutSeconds: '60'
runCommand:
- "bash service_restart_script.sh {{slackChannel}} {{slackToken}}"I have defined two parameters in this Command document: one for the Amazon S3 path where the bash script is located, one for the Slack API token. Here, we have two actions: aws:downloadContent downloads the script from Amazon S3 and aws:runShellScript executes the bash script.
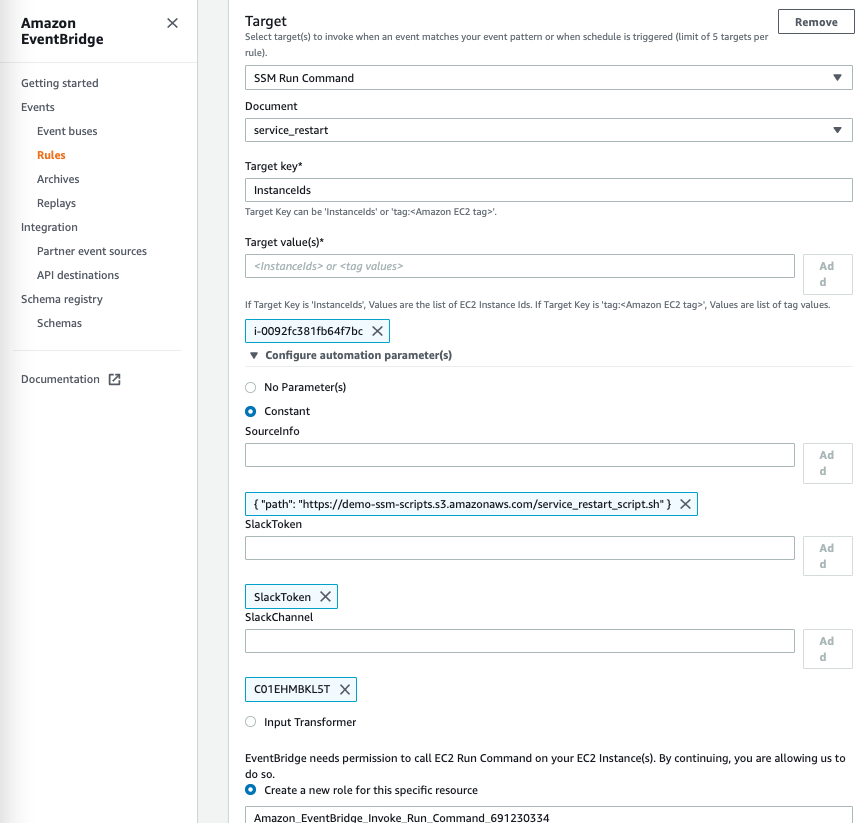
EventBridge setup: We now need an EventBridge rule that can trigger the AWS Systems Manager Run Command. Navigate to the EventBridge console. Under rules, create a new rule. Under Define pattern, choose pre-defined pattern by service and select All events from the Service provider drop-down menu.
Select the custom event bus that was created in Datadog. We need to select the target. Choose AWS Systems Manager Run Command as the target and select the document. The AWS Systems Manager Run Command that we created earlier was an Amazon EC2 instance, so keep instanceIds in key and the Amazon EC2 instance ID in value.
Select the constant under Configure automation parameters and provide the values as follows:
sourceInfo: { “path”: “<S3 object url for bash script>” }
slackToken: <SSM parameter name that contains Slack’s token secret>
slackChannel: <Slack channel Id>
After that, initialize your event bus under Event buses in the Amazon EventBridge console. The setup is complete at this point, and now it’s time to test it.
We can trigger a test alert in Datadog or manually stop the NGINX process in Amazon EC2. As a result, the service down alert triggers the AWS Systems Manager Run Command, which will restart NGINX and share the recent logs on Slack, as shown below:

For more information on runbook automation and reducing MTTR, see these related blog posts:
How to get on board with 24/7 support that delivers reduced MTTR faster
Need help with 24/7 Support or Site Reliability Engineering? nClouds’ Site Reliability Engineering Services for AWS help keep your systems fast and reliable, with maximum uptime as they scale — so your engineers can focus on innovation. Contact Us.


